
Why Is IBM Rising Again
IBM’s Real Technical Moat and the Question of an AI-Era Re-Rating


In late May, a video of Trump saying IBM stock would go much higher made the rounds. A lot of people took it as a buy recommendation. But it was not something he said recently. The remark came from a White House Business Roundtable on December 10, 2025, and resurfaced five months later.
At that event, Trump called IBM CEO Arvind Krishna a legend and credited him with pushing the stock up to a good price. It was closer to praise for the CEO than a call to buy. What sent the clip spreading again, stripped of its context, was the May 21 announcement of a quantum foundry by IBM and the U.S. Commerce Department.

The timing is strange. The same stock dropped 13% in a single day back in February, just three months earlier. That was its worst single-day decline in 25 years. Then, after sliding to a 52-week low in mid-May, the stock jumped more than 30% in two weeks as the quantum announcement and the Trump video overlapped, climbing back near its all-time high. The fundamentals did not change in between. Same quarter, same business, same management.
This piece is about how to read that surge.
Whether IBM has a real technical moat, how that moat shows up in revenue, whether an AI-era re-rating is genuinely on the table, and whether the current price is expensive or cheap.
The short version is that IBM is a solid company.
But being solid and being a good buy right now are two different things. This piece follows that distinction all the way through.
Contents
Is IBM’s Technical Moat Real
Layer One: Spyre, an Inference Chip Outside the Price War
Layer Two: Inference Brought Inside the Transaction
Layer Three: Software Lock-In
Where the Revenue Comes From
Is an AI-Era Re-Rating Genuinely Possible
Quantum as an Option
The Investment View: Expensive or Cheap
Closing
Disclaimer
This is an analysis written for informational purposes and does not recommend buying or selling any security. Responsibility for investment decisions and their outcomes rests entirely with the individual. The figures in this piece are as of the time of writing, and the analysis and outlook sections reflect the author’s personal views.
Is IBM’s Technical Moat Real
IBM’s moat is not marketing rhetoric. It is real.
What matters is drawing a precise line between where the moat exists and where it does not. IBM’s moat has three layers. At the innermost layer sits an inference chip, on top of that the mainframe, and on the outermost layer software lock-in.
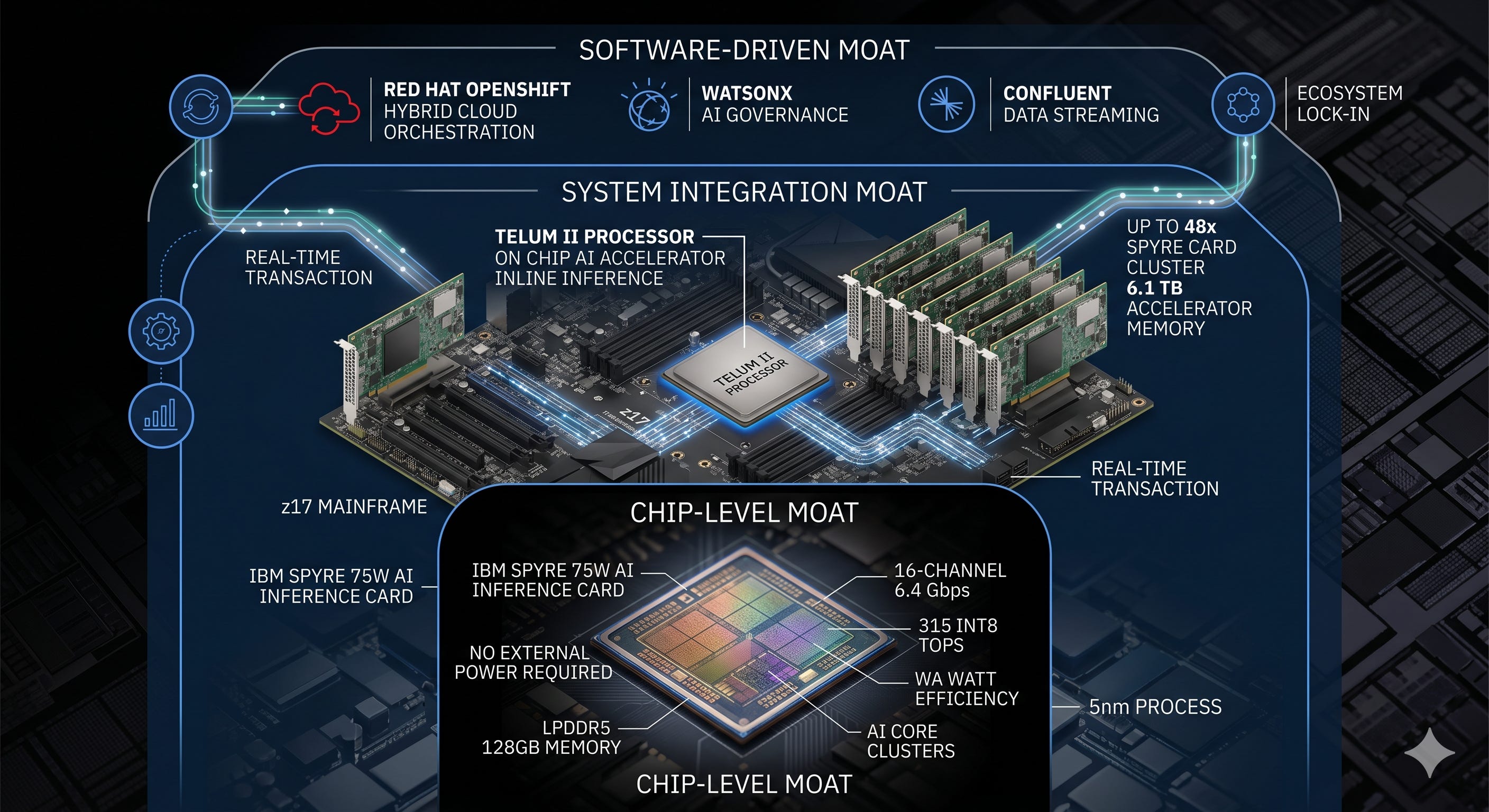
Layer One: Spyre, an Inference Chip Outside the Price War

In early 2026, at ISSCC, IBM disclosed the technical details of an AI inference chip called Spyre. It is a PCIe card that plugs into mainframes and Power servers. The key point is that this is not a product built to compete with NVIDIA GPUs. The single constraint that creates that difference is power.
Spyre is a 75-watt single-slot card with no auxiliary power connector. It draws only the 75 watts the motherboard slot provides. Its direct comparison is a single-slot inference card like the NVIDIA L4, not an H100 or B200 that pulls anywhere from 700 watts to several kilowatts. Why it was capped at 75 watts explains everything. IBM’s customers are banks, insurers, and governments. They process tens of thousands of transactions per second inside the mainframe, in milliseconds. To run an AI judgment like fraud detection without sending data outside, inside the very system where the transaction happens, the chip has to slot into an existing mainframe with no additional power. So, 75 watts.
That constraint dictated the memory choice too. HBM draws too much power to fit inside 75 watts, so IBM went with LPDDR5. Sixteen channels at 6.4 Gbps give 204 GB per second of bandwidth and 128 GB of capacity per card. It is a choice that trades bandwidth for capacity. The NVIDIA L4 has 24 GB; Spyre has 128 GB. The specs are a 5nm process, a 330 square millimeter die, 25.6 billion transistors, and 32 AI cores. At 315 INT8 TOPS and 4.2 TOPS per watt, its efficiency leads the L4 within the single-slot inference card category.
Here is where the IBM character shows. Spyre took eight years, three process nodes, and five generations of test chips before a production part arrived. The concept began at IBM Research in 2015, and the first prototype was shown in 2018, before the industry had even decided whether inference-dedicated silicon was worth building. It is the opposite of an AI chip startup shipping its first generation in two or three years.
So Spyre’s moat is not in performance but in position. The inference chip market right now is a price war with d-Matrix, Groq, Furiosa, Rebellions, and Qualcomm all lined up. IBM is not in that fight. A bank uses Spyre not because its TOPS per watt beats the competition, but because the chip goes inside the z17. However far inference chip prices fall, IBM’s place is somewhere that price tag cannot reach.
Layer Two: Inference Brought Inside the Transaction
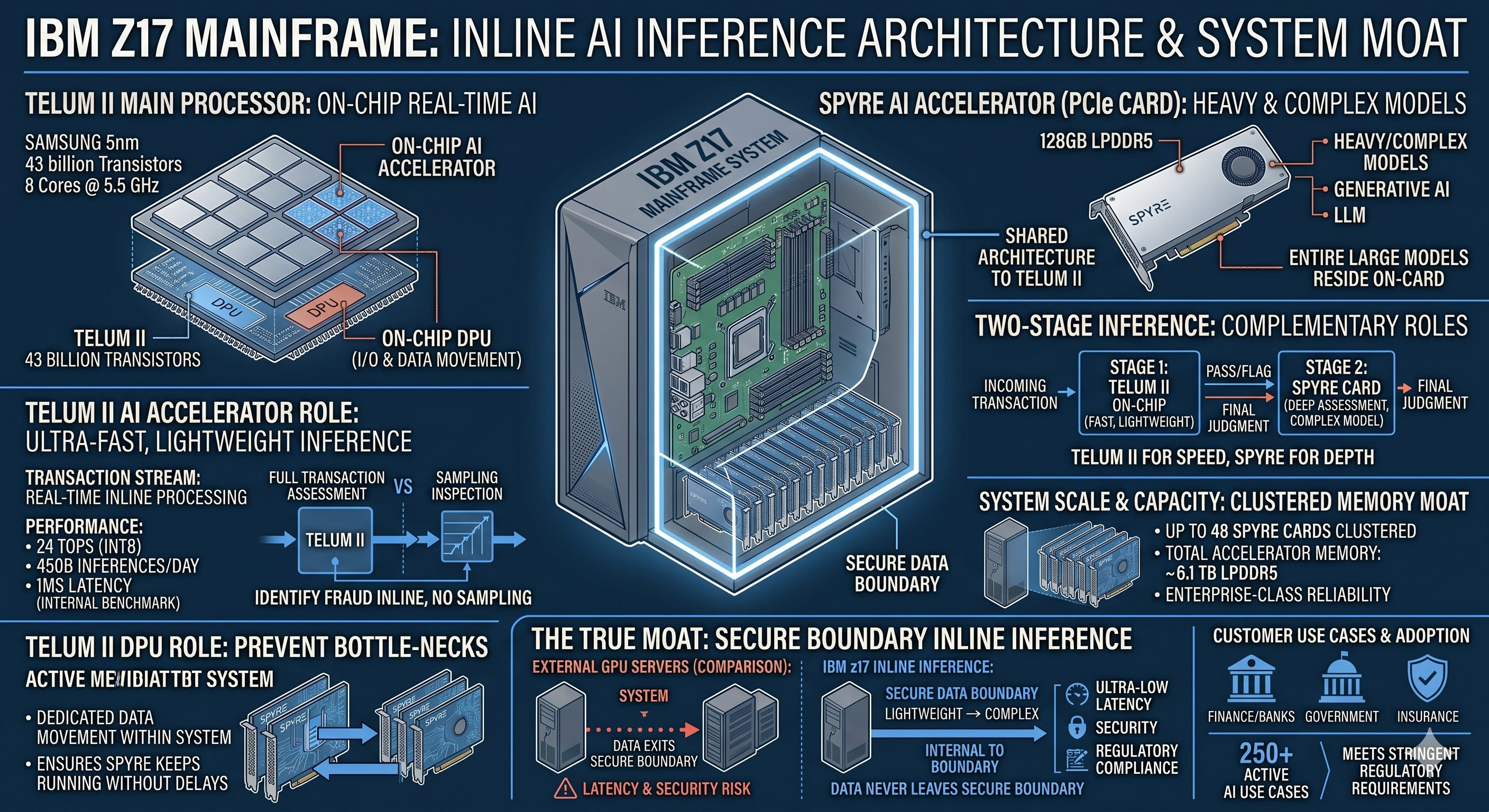
A single chip does not make a moat. What matters is where it plugs in. Spyre does not work alone; it pairs with the z17’s main processor, Telum II. IBM designs Telum II and Samsung manufactures it on 5nm. It has 43 billion transistors and 8 cores at 5.5 GHz.
Two things are built into this chip. One is an on-chip AI accelerator, an AI compute circuit placed directly inside the processor that handles light inference instantly within the transaction flow. The figures IBM cites, 450 billion operations a day at 1-millisecond response, are from an internal benchmark using a specific fraud detection model. The other is a DPU, a dedicated input/output circuit. IBM gave up the space of two cores in the z17 to add it. This dedicated circuit takes over data movement so that no bottleneck forms when Spyre runs a heavy model.
The roles divide cleanly. Light, fast inference runs inside the Telum II processor; heavy, complex models go to Spyre on the card. Cluster up to 48 Spyre cards in a single IBM Z or LinuxONE and the system holds roughly 6.1 terabytes of accelerator memory.
This is the real moat. If a bank sends fraud detection AI out to an external GPU server and back, latency appears and sensitive data leaves the system. The z17 runs inference inline, right where the transaction is processed. The data never crosses the security boundary once. In heavily regulated finance and government, this is not a preference but a requirement, and bolting on an external GPU struggles to meet it.
One thing to be clear about here. These chips are not headed into the AI infrastructure market where NVIDIA plays. Neither Spyre nor Telum II plugs into anything but IBM Z, LinuxONE, and Power. There is no strategy to sell them externally as standalone chips, and they have nothing to do with GPU market share. So the picture of IBM taking on NVIDIA with AI chips, or becoming an AI infrastructure stock on the back of a chip, does not hold. The value of these chips is not in capturing the GPU market but in binding mainframe customers more tightly.
Layer Three: Software Lock-In
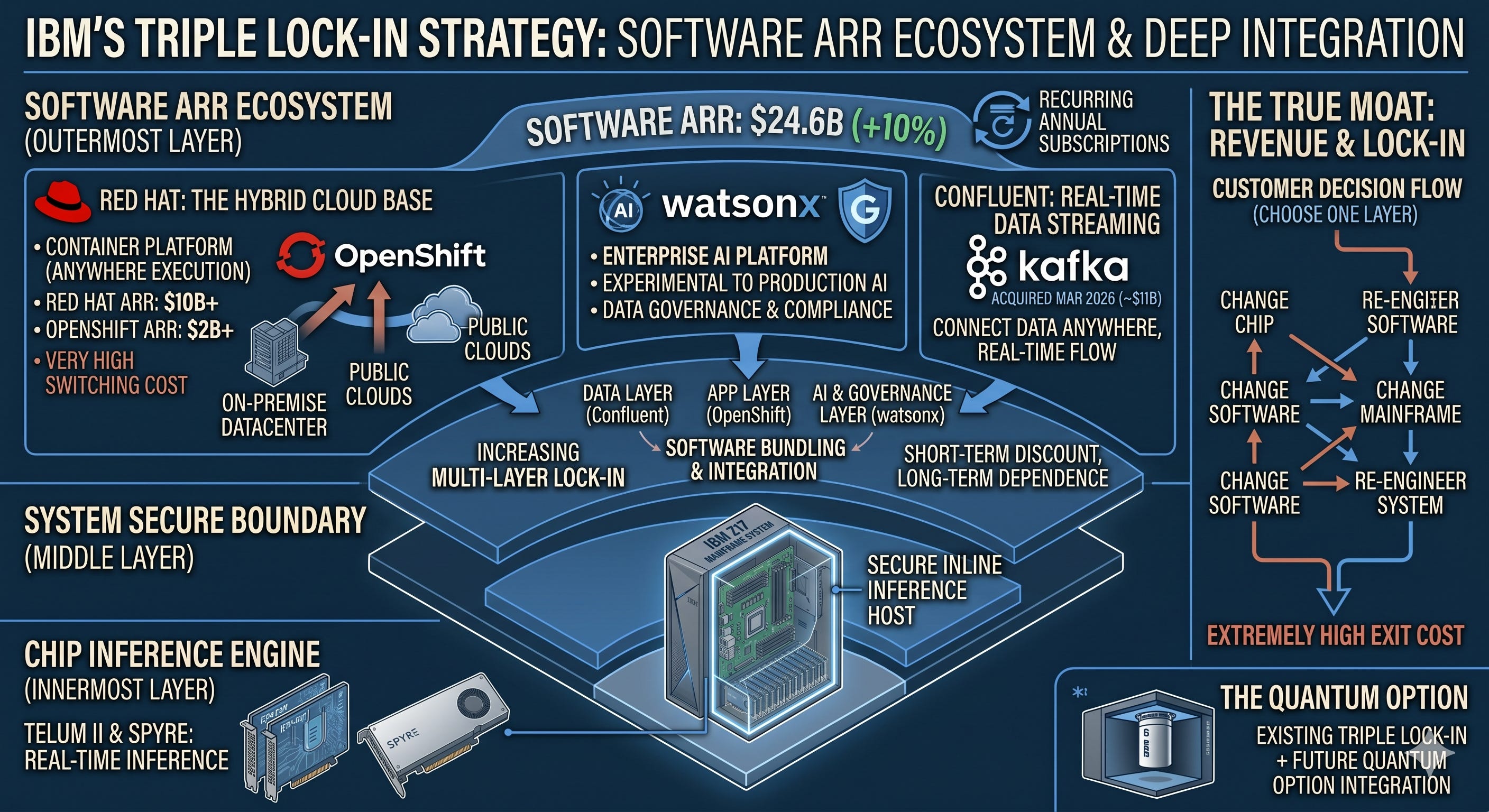
The outermost layer, and the asset that contributes the most revenue, is software. IBM’s software annual recurring revenue (ARR) is $24.6 billion, up 10% from a year earlier. This is not a license you sell once and are done with; it is revenue that comes in every year.
At the center sits Red Hat. It sells enterprise Linux and a container platform called OpenShift. When a company runs systems across its own data center and multiple clouds, OpenShift lays the floor underneath. It has reached around $2 billion in ARR, and once a company builds its systems on top of that floor, swapping the floor out becomes very hard.
On top of that IBM has layered watsonx (a platform for running AI on a company’s own data while maintaining governance) and Confluent (real-time data streaming), acquired in 2026 for roughly $11 billion. The picture is one of weaving together the layer that connects data, the layer that runs apps, and the layer that adds AI. Use IBM for one layer and it becomes easier to use IBM for the rest, and the deeper you go, the higher the cost of leaving. For a company that is a point of caution; for an investor it is a moat.
Put the three layers together and it becomes clear. The chip runs inference at the point of the transaction, the mainframe holds it inside a security boundary, and the software ties together data, operations, and AI. Lifting out a single layer is very hard. Changing the chip means changing the mainframe, and changing the software means rebuilding the entire system above it. This is IBM’s real moat, the one with substance behind it.