

Memory got expensive and supply is short.
Everyone knows that much. But if you read this as an ordinary supply-demand problem of rising prices and tight volumes, you miss what is actually happening. The price increase is just a symptom. Underneath it sits a structural ceiling on supply that does not loosen easily even when demand cools.
DRAM prices are not rising because demand piled up. They are rising because of a bottleneck that keeps you from making the parts on time even when you want to.
In a simple supply-demand story, prices fall when demand bends.
In a structural bottleneck, the shortage runs long regardless of demand.
The companies that understood this difference stopped waiting for prices to drop and started moving differently. They are digging routes that use less DRAM.
AMD buying MEXT, an Israeli software startup, this week is a clean example.
MEXT builds a prediction layer that lets flash behave like DRAM. It is neither an AI chip nor a memory maker. Understand why AMD bought a software company like this now, instead of a chip or a memory part, and you can see the memory market of the next few years.
This piece breaks that detour technology into nine tracks. For each one, I look at why it works, where it breaks, and which companies are moving how right now, from an engineer’s point of view. On top of that I lay a bigger question. When and how will these technologies combine to dissolve the memory tax, and who holds the initiative in that process.
The goal is to tie market, supply, and technology into one picture.
Contents
Anatomy of the memory tax
First, memory is stacked in layers
Why AI eats memory like this
Why this is not a cycle
Why adding capacity does not solve it
The two asymmetries that make NAND the choice
Changing the medium
Track 1: HBF, putting flash in HBM’s seat
Track 2: 3D memory-logic stacking, HBM’s next move
Cutting data movement
Track 3: PIM and PNM, bringing compute to the memory
Track 4: Optical memory interconnect, joining memory and compute with light
Solving It at the System and Software Level
Track 5: CXL, pooling and expanding memory
Track 6: Predictive tiering, software promoting a medium into memory
Track 7: Algorithmic compression, shaving demand itself
Track 8: On-device sparse, fitting the model to the medium
Track 9: Module innovation, supplying capacity on paths outside HBM
Beyond the tracks: SRAM inference chips and new-material memory
The SRAM route: chips that skip HBM
New-material memory: reweaving the material
So how does the memory tax get solved
The nine tracks are not competition, they are division of labor
Look on a time axis and the order appears
The key insight: the HBM profitability reversal changes everything
The dynamics of the board: who fights whom
Front 1: hyperscalers have started to own the standard
Front 2: Nvidia seizes the entire memory hierarchy as interface
Front 3: the line between memory and foundry collapses
Front 4: the standards war decides where the margin sits
Signals to watch from here
Conclusion
This piece is technical and industry analysis for informational purposes and does not recommend buying or selling any security. Company names appear only as examples to illustrate technology trends and are not investment recommendations. The figures and schedules in the text are based on public information available at the time of writing and may change afterward. Responsibility for investment decisions and their outcomes rests entirely with the reader.
1. Anatomy of the memory tax
First, memory is stacked in layers
A computer’s memory is not one thing. It is a hierarchy stacked top to bottom. Higher up it is fast but expensive and small. Lower down it is slow but cheap and large. Closest to the compute unit, at the very top, sits SRAM cache, then DRAM below it, then NAND flash below that, with HDD at the bottom. The system runs this hierarchy by keeping frequently used data in the upper floors and rarely used data in the lower ones.
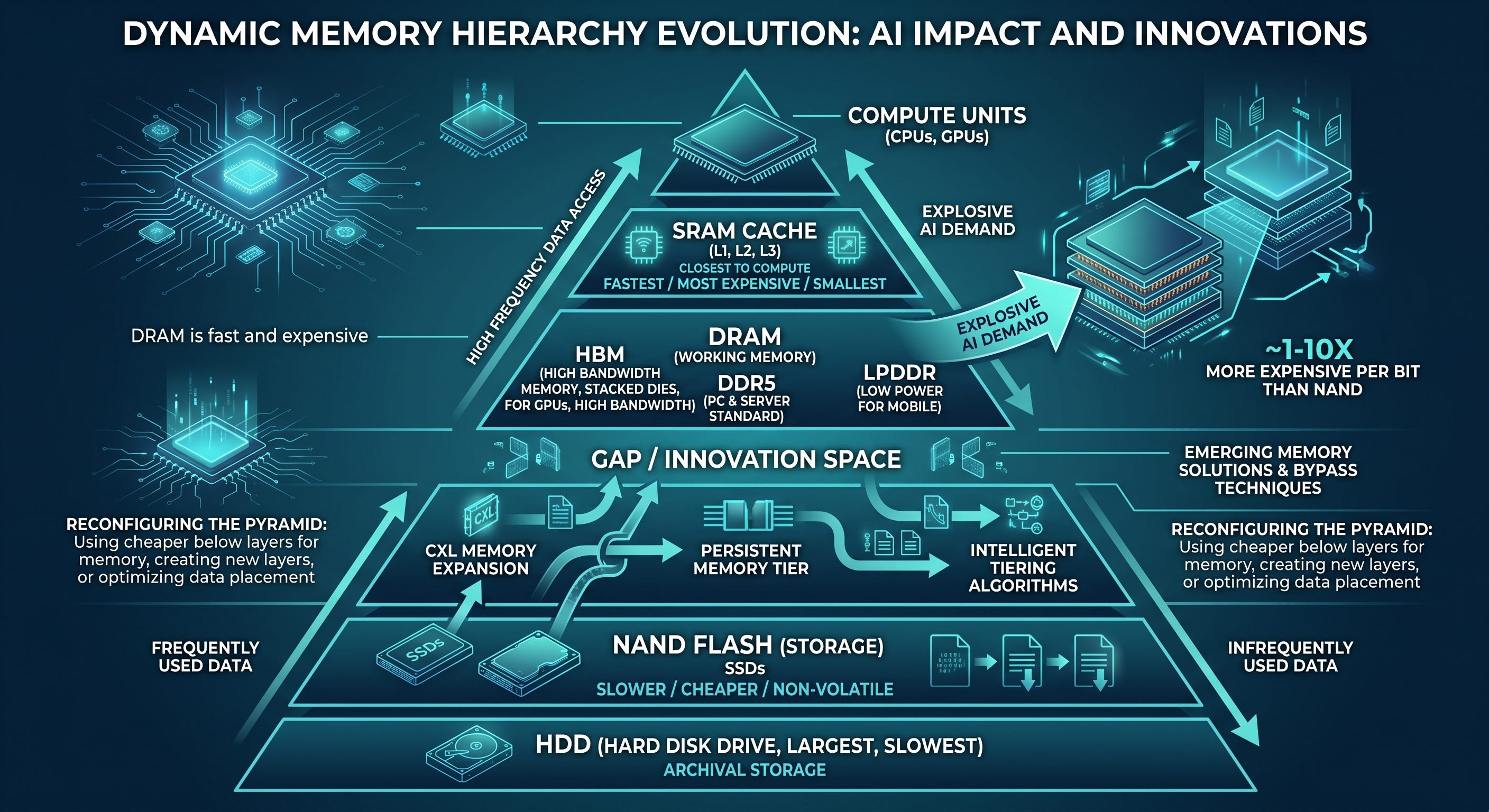
What matters for this piece is the middle two floors, DRAM and NAND. DRAM is the fast, expensive working memory that holds the data being computed right now. Even within DRAM the uses diverge. HBM (High Bandwidth Memory) is the fast GPU version that stacks DRAM dies vertically and ties them together over a wide path to push bandwidth up. DDR5 is the standard version for servers and PCs. LPDDR is the low-power version that prioritizes power efficiency. All three are the same DRAM technology, differing only in what they prioritize. NAND flash is the slow but cheap storage medium that keeps data even when power is cut. It is what sits inside an SSD. On a per-bit basis NAND is far cheaper than DRAM, anywhere from a single-digit to tens of times less.
The key is that this hierarchy is not fixed. AI is twisting the pyramid. As HBM explodes, the top floor bloats, and the DRAM below it starves as its capacity is taken away. So a fight breaks out over the wide empty gap between fast DRAM and cheap NAND. The nine detour technologies this piece covers are all attempts to touch this pyramid. They pull the cheap lower floor up in place of the expensive upper one, or they slot a new floor between two existing ones, or they place data more cleverly across the floors.
Why AI eats memory like this
AI eats this much memory along two axes. One is model parameters, the model’s weights themselves. The other is the KV cache (Key-Value Cache). The KV cache is the record storing the context of every word the model has read so far, and it gets re-read in full each time a new word is generated. The longer the conversation, the larger the cache grows, so in long contexts a single request can reach tens of GB, and far more when concurrency rises. In long-context inference the KV cache becomes the bottleneck before the model weights do. Most of the detour technologies that follow ultimately solve the question of which floor of the pyramid to put this KV cache and these parameters on.
Will the Memory Stock Rally Keep Going?

SK hynix posted 72% operating margin in a single quarter. Micron is locking in 3-to-5-year supply agreements. Samsung had a quarter where conventional DRAM profitability exceeded HBM.
Why this is not a cycle
Start with exactly what that structural bottleneck is. The market reads today’s shortage as “DRAM is expensive, the three memory makers are booming, the cycle has peaked.” But reading the cause of the shortage as demand alone leads to the wrong conclusion that it ends when demand cools. This time is different.
Memory is no longer a cyclical industry.

I had the chance to attend a seminar by SK Hynix’s North America regional president at a Silicon Valley Korean semiconductor meetup today. The topic was memory in the AI era. It was only about 20 minutes, but it was packed with insight on the structural shifts reshaping the memory market, the technical roadmap for HBM, and things investors genuinely need to understand.
The cause is the time-inelasticity of supply. This is not a shortage that clears the moment demand cools, but one where process and capacity allocation are physically locked. HBM consumes far more capacity per wafer than standard DRAM. By Micron’s published numbers, HBM consumes wafer capacity against DDR5 at three to one. Making one HBM part erases the capacity worth of three standard DDR5 parts. By bit supply share HBM goes from about 8 percent in 2025 to roughly 13 percent in 2027, but on a wafer-start basis it goes from 18 percent to 30 percent over the same period. Because the die is far larger, the real capacity erosion runs far ahead of the bit share.
The result is that the standard chips destined for phones and PCs get physically pushed out of fab space. By TrendForce’s tally, first-quarter DRAM contract prices jumped 90 to 95 percent quarter over quarter, with a further 58 to 63 percent rise expected in the second quarter. There was even a price inversion where DDR4 became more expensive than DDR5. An older part costing more than a newer one is a signal that cannot appear in a normal market. It is evidence that supply is being pulled out of a specific segment wholesale, regardless of demand.
Why adding capacity does not solve it
Growing new DRAM bits requires EUV scaling. A single scanner runs 200 million dollars, a cleanroom runs tens of billions per fab, and completion takes years. Micron’s Idaho fab does not come online until 2027, and the new lines at SK hynix Yongin and Samsung Pyeongtaek and Taylor see first shipments in 2027 to 2028. Even those, management has nailed down, get allocated first to HBM and high-margin enterprise DRAM through 2027.
There is one more decisive variable here. The three memory makers have decided not to expand aggressively. Samsung and SK hynix together hold about 70 percent of global DRAM, and they have signaled to investors that they will not grow capacity aggressively. The pattern from past cycles, where rising prices triggered a capacity race that created a glut, they are deliberately not repeating this time. It is a discipline that puts profitability ahead of volume.
Put it together and the shortage is structural. Process is bound to time, new fabs do not arrive until 2027, even those go to HBM first, and the three makers hold back expansion. Analyst consensus puts meaningful easing at the second half of 2027 at the earliest, with normalization in 2028 to 2029. Intel’s CEO said there is no stability until 2028. Some see it running past 2028 if AI investment does not bend.
The two asymmetries that make NAND the choice
When capital picks a detour, NAND often becomes the endpoint because two asymmetries are at work.
One is cost.
On a per-bit basis flash is roughly a single-digit, and as much as 50 times or more, cheaper than DRAM. This is not a gap to close with optimization. The order of magnitude itself is different.
The other is process.
NAND grows capacity not by EUV scaling but by stacking cells vertically. Because it is a deposition and etch process upgrade, it uses tools the fab already has. Controllers are made on mature 6 and 7 nanometer nodes. It sits outside the leading-edge crunch that throttles everything.
That said, NAND is tight right now too. As enterprise SSD demand explodes, TrendForce puts second-quarter NAND contract prices up 70 to 75 percent, overtaking DRAM’s rate of increase for the first time. The difference is that NAND has an open road to grow bits through stacking. It is a different kind of bottleneck from DRAM’s EUV constraint. So every technology that “uses NAND as memory in place of DRAM” gains value at the same time.
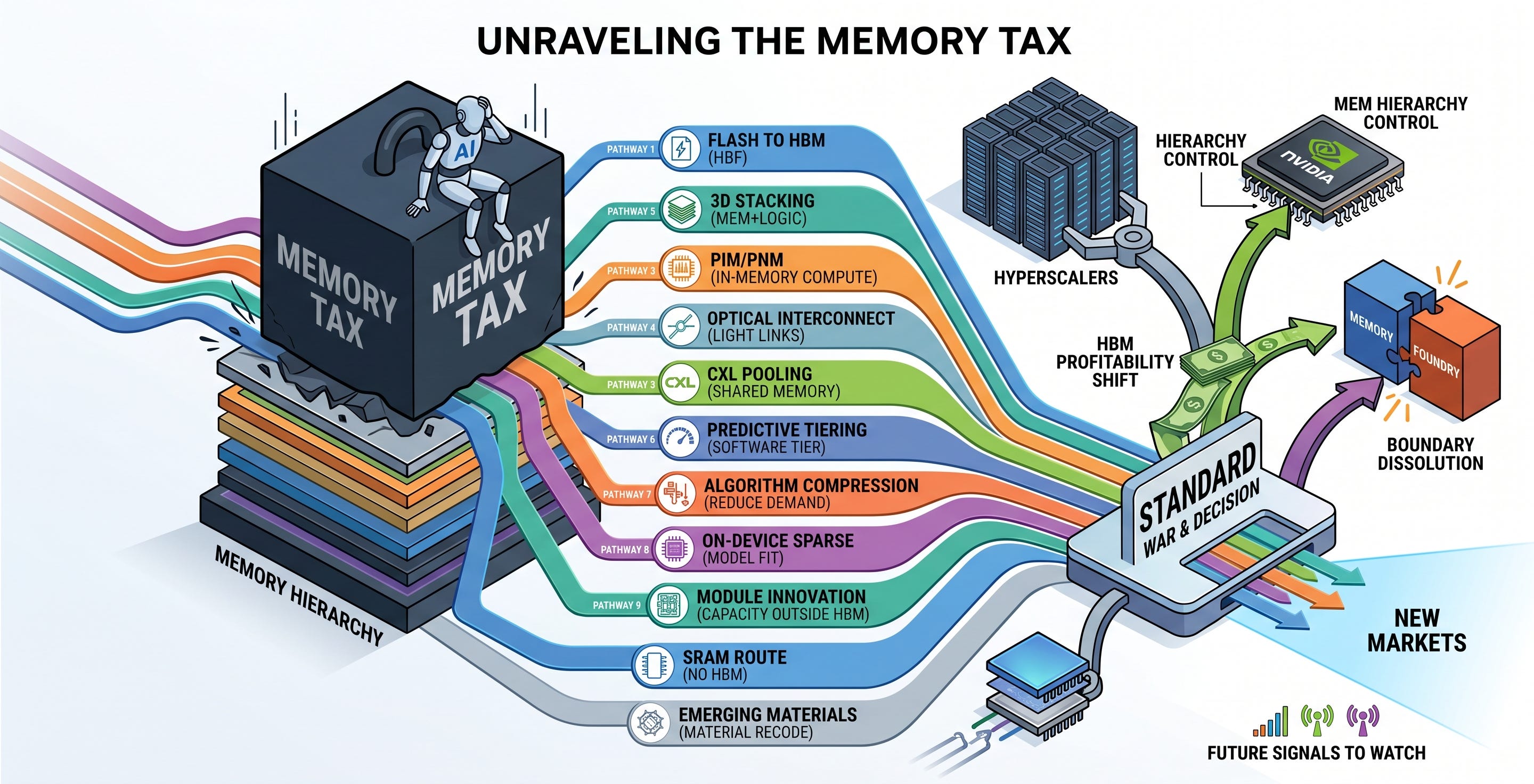
The workarounds fall into three groups: changing the medium, cutting data movement, or expanding and economizing memory at the system and software level. The nine routes sort into these three groups. Here is the whole landscape on one page.
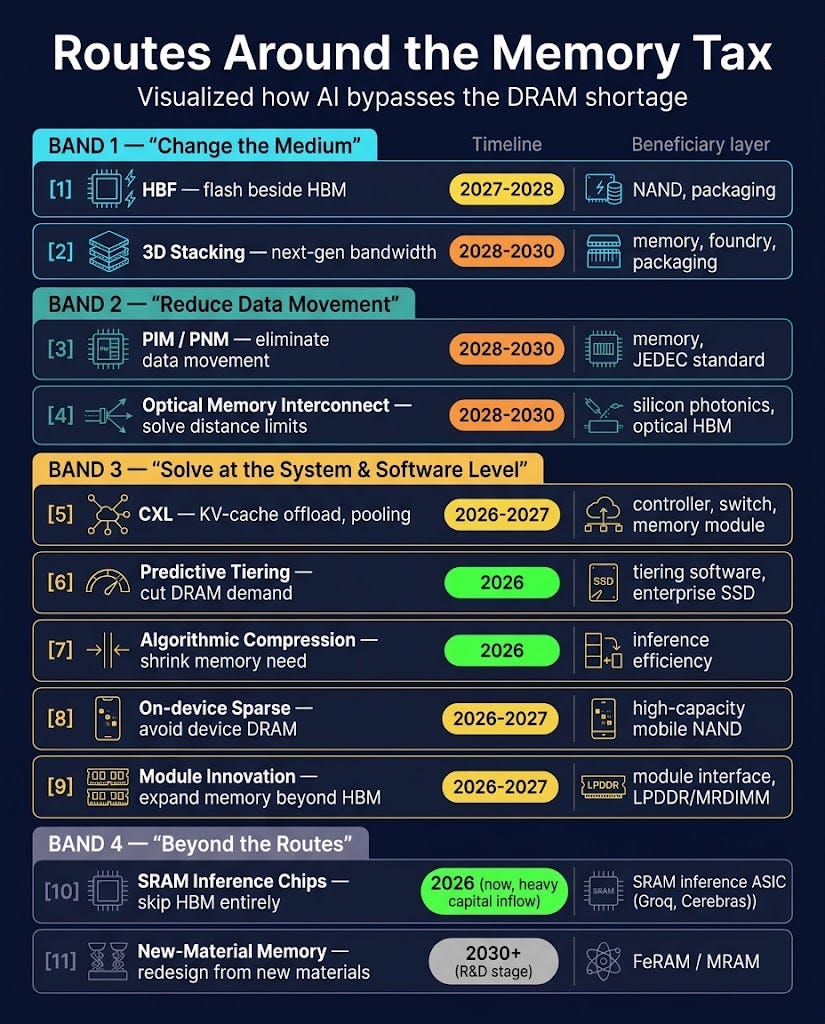
From here on, I take each detour technology apart one by one: how far it has actually come, where it breaks, and which companies hold the initiative at which layer.